使用学生表和成绩表来演示连接,SQL架构如下:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
Create table If Not Exists student_info (id int, name varchar(255));
Create table If Not Exists student_score (id int, score int);
Truncate table student_info;
insert into student_info (id, name) values ('1', 'Wang');
insert into student_info (id, name) values ('2', 'Alice');
insert into student_info (id, name) values ('3', 'Allen');
Truncate table student_score;
insert into student_score (id, score) values ('1', '65');
insert into student_score (id, score) values ('2', '70');
insert into student_score (id, score) values ('3', '75'); |
执行连接查询的语句如下:
注意id为3的学生没有成绩记录,如下:
| 代码块 | |
|---|---|
| 代码块 | |
| language | sql | theme | DJango
mysql> SELECT * FROM student_score, student_info; +------+-------+------+-------+ | id | score | id | name | +------+-------+------+-------+ | 3 | 75 | 1 | Wang | | 2 | 70 | 1 | Wang | | 1 | 65 | 1 | Wang | | 3 | 75 | 2 | Alice | | 2 | 70 | 2 | Alice | | 1 | 65 | 2 | Alice | | 3 | 75 | 3 | Allen | | 2 | 70 | 3 | Allen | | 1 | 65 | 3 | Allen | +------+-------+------+-------+ 93 rows in set (0.00 sec) |
上面的连接查询直接把多表放在了FROM后面,用逗号进行间隔,所以是内连接,与下面的语句是等效的:
| 代码块 | ||||
|---|---|---|---|---|
| ||||
mysql> SELECT * FROM student_info JOIN student_score; +------+-------+------+-------+ | id | name | id | score | +------+-------+------+-------+ | 3 | Allen | 1 | 65 | | 2 | Alice | 1 | 65 | | 1 | Wang | 1 | 65 | | 3 | Allen | 2 | 70 | | 2 | Alice | 2 | 70 | | 1 | Wang | 2 | 70 | | 3 | Allen | 3 | 75 | | 2 | Alice | 3 | 75 | | 1 | Wang | 3 | 75 | +------+-------+------+-------+ 92 rows in set (0.00 sec) |
从结果来推导一下内连接的行为。
首先,连接的关键字是join,join是一个及物动词,比如A join B,字面上的意思就是A加入B,或者说A成为B的一员,这里B是主导,而A是次要。
回到SQL中的join。SQL在生成连接时,默认生成的是笛卡儿积,也就是从一个表中取出一条记录,然后和另一个表的全部记录组合。这里到底是先取哪个表,就是根据join来定的。比如student_info JOIN student_score,这种写法下,student_score表是主导,student_info表是次要,student_info表负责“加入”student_score表,所以先取的记录来自于student_score表中,这也可以通过上面的结果得到验证。来自student_score表的列虽然位于结果集的右侧,但是结果集的顺序是按顺序先取student_score表的记录,再组合全部的student_info表记录。
| 提示 |
|---|
虽然 |
接下来讨论一下关于连接的过滤条件,还是先以内连接为例。
对于连接的过滤,有两个层次,第一层是在生成临时表时起作用,第二层是在临时表生成后再起作用。这两层对应关键字ON和WHERE。
ON作用于临时表的生成。两表在连接时默认生成笛卡尔积,这个结果有可能规模巨大。加入ON条件进行过滤后,可以减小临时表的规模。
WHERE在临时表生成之后起作用,这时已经没有连接的概念了。
虽然作用机制不同,但在内连接中,ON和WHERE实现的效果是一样的,以下是ON和WHERE的示例:执行一次典型的外连接查询,查询所有学生的成绩,不管其有没有成绩记录,如下:
| 代码块 |
|---|
mysql> SELECT * FROM student_info LEFT JOIN student_score ON student_info.id = student_score.id; +------+-------+------+-------+ | id | name | id | score | +------+-------+------+-------+ | 1 | Wang | 1 | 65 | | 2 | Alice | 2 | 70 | | 3 | Allen | NULL 3 | NULL 75 | +------+-------+------+-------+ 3 rows in set (0.00 sec) |
以下是关于外连接和ON的一些解释。
以左外连接为例,左外连接的目的是取出左表的每一行,然后和右表的所有行进行匹配,如果有符合ON条件的行,就输出组合后的结果,如果右表遍历后连没有一条符合ON条件的记录,就用NULL值替代右表,再进行组合后输出。
如果ON条件设置为1,也就是无论左表的记录是什么,右表的所有行都符合条件,那么外连接的查询就和笛卡尔积是等价的,如下:
| 代码块 |
|---|
mysql> SELECT * FROM student_info LEFT JOIN student_score WHERE student_info.id = student_score.idON 1; +------+-------+------+-------+ | id | name | id | score | +------+-------+------+-------+ | 1 | Wang | 2 | 70 | | 1 | Wang | 1 | 65 | | 2 | Alice | 2 | 70 | | 2 | Alice | 1 | 65 | | 3 | Allen | 2 | 70 | | 3 | Allen | 75 1 | 65 | +------+-------+------+-------+ 36 rows in set (0.00 sec) |
外连接一定要on,参考:https://cloud.tencent.com/developer/ask/206061
参考:
SQL JOIN Types Explained | LearnSQL.com在外连接中,ON子句是必需的,不能省略。比如左外连接,生成的结果集一定包含左表的所有行,而对于右表取哪些行,就通过ON子句来指定,注意这里的ON子句的结果已经不重要了,重要的是ON子句指定了右表如何匹配左表。
贴一张图以助于理解:
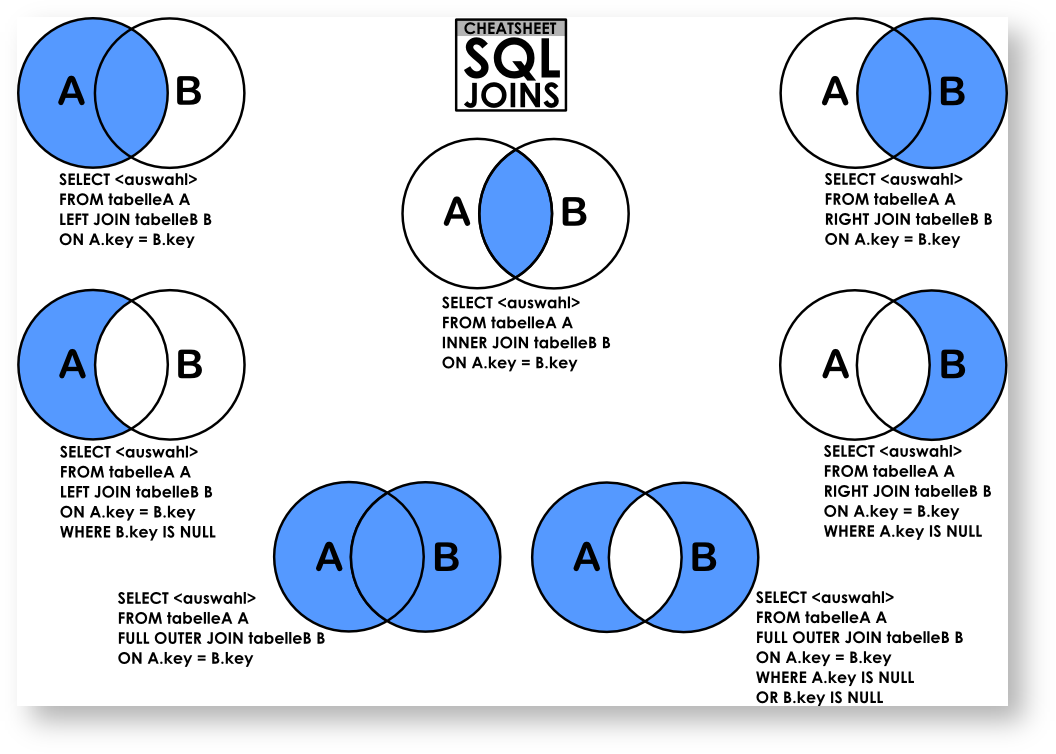
| 目录 |
|---|