Step1 - 理解需求,确定设设计范围
确定系统需求,比如:
- ID有什么要求?
- 必须按1自增吗?
- 必须是数字吗?
- 长度有什么要求?
- 系统规模如何,生成速度有什么要求?
这里以下列需求作为本系统的设计需求:
- ID必须唯一
- ID必须是数字类型
- ID长度是64bit
- ID按时间递增
- 每秒能够生成10000个唯一ID
Step 2 - 高阶设计
有几种常见的方式用于在分布式环境下生成唯一ID:
- 多主机复制模式
- UUID
- 发号服务器
- Twitter雪花算法
多主机复制模式
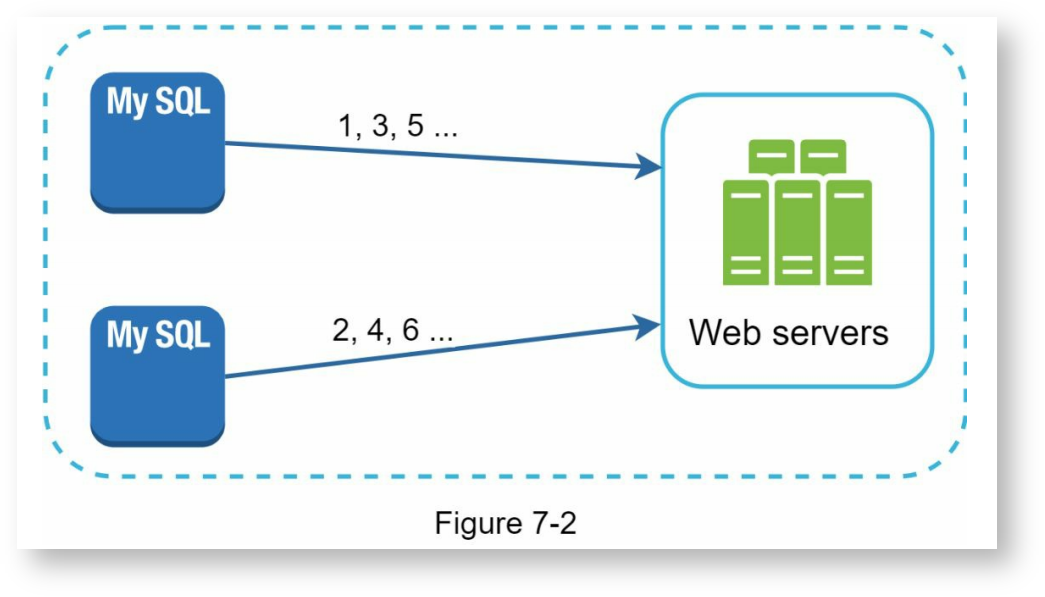
通过多个数据库的自增主键来生成唯一ID,不同的服务器从不同的基数开始,每次按k进行自增,这里k是服务器的数量,比如上面的示例,服务器1按1,3,5...的顺序生成ID,服务器按2,4,6...的顺序生成ID。
多主机复制模式在某种程度上解决了扩展问题,但也有几个重大缺陷:
- 难以跨数据中心进行扩展
- 不能保证在多个服务器上生成的ID是按时间递增的
- 不好处理有服务器新增或删除的情况
UUID
128位的唯一ID,由算法保证唯一性,各个服务器之间无须进行同步即可独立生成UUID。UUID的冲突概率极低,按维基百科的描述,每秒生成10亿个ID,连续生成100年,才有可能达到生成一个UUID时有50%的概率重复,以下是一个UUID的示例:
09c93e62-50b4-468d-bf8a-c07e1040bfb2
优点:
- 算法简单,且无须同步
- 极易扩展
缺点:
- 长度固定为128位,无法调整
- ID不随时间增长
- ID可能为非数字类型
发号服务器
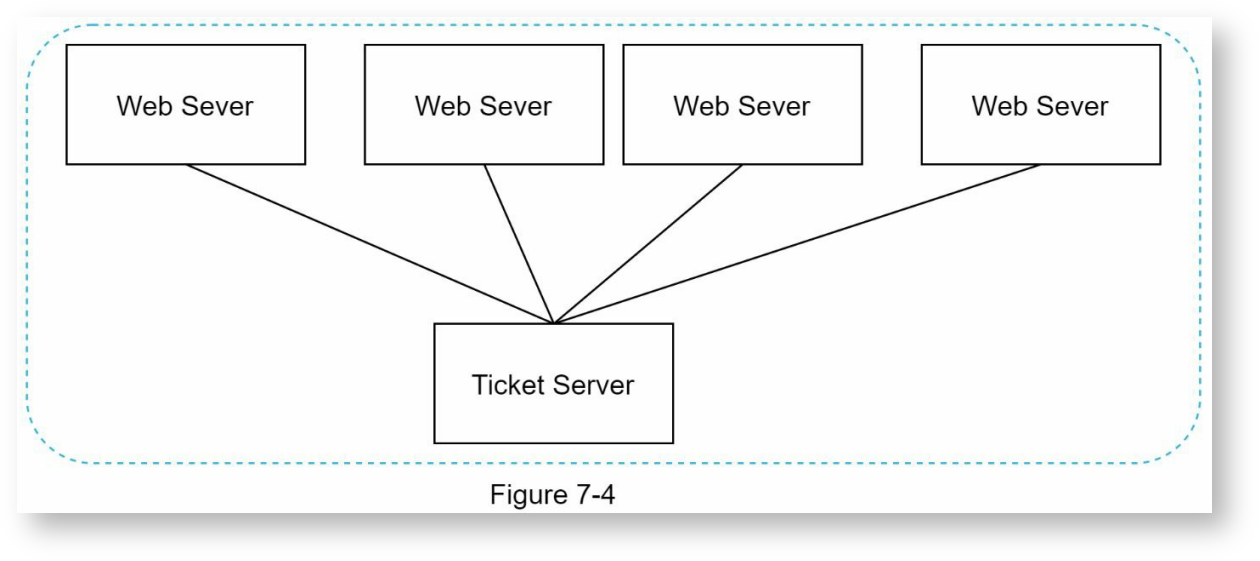
使用中心化的发号服务器来生成ID,内部的实现仍然是数据库的自增主键。
优点:
- ID为数字形式
- 非常容易部署,很适合小规模系统
缺点:
- 单点故障问题,如果发号服务器宕机,则整个系统都会出问题。解决方式是多设置几个发号服务器,但会引入数据同步问题。
Twitter雪花算法
采用分治的思想,将ID分成几部分,每部分独立生成,从面保证ID的唯一性,以下是一个64位的ID分布:采用分治的思想,将ID分成几部分,每部分独立生成,从而保证ID的唯一性,以下是一个64位的ID分布:
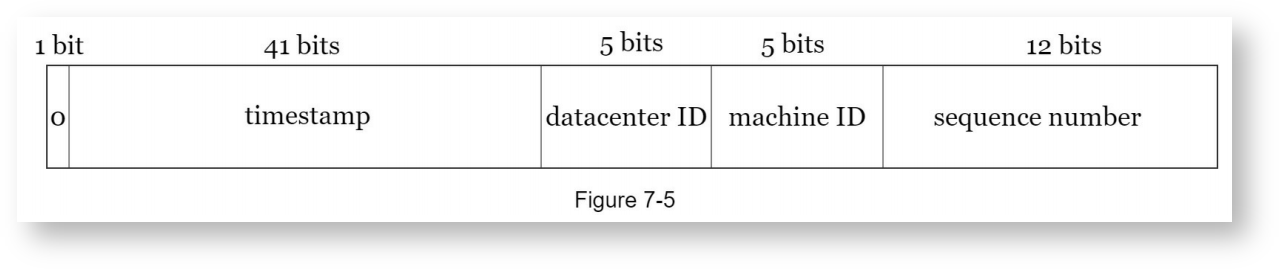
每部分描述如下:
- 符号位:1bit,总是为0,当前未使用,用于后续扩展。符号位:1bit,固定为0,当前未使用,用于后续扩展。
- 时间戳:41bit,从一个预定的时间点开始到现在的毫秒数,Twitter使用的时间点是2010-09-04 01:42:54 UTC。UTC,转化成毫秒数是1288834974657。
- 数据中心编号:5bit,最多支持32个数据中心。
- 机器编号:5bit,每个数据中心最多支持32台机器。
- 序列号:12bit,每个机器的序列号按1自增,在下一个毫秒置为0,也就是说,单个机器每毫秒最多可生成4096个ID。
Step 3 - 详细设计
使用雪花算法作为分布式ID生成算法,数据中心编号和机器编号在一开始时就应该确定下来,因为后续调整这两个编号将极为麻烦,容易导致ID冲突。
雪花算法的时间戳为41bit,单位为毫秒,一共可表示的时间长度是 2^41 -1 = 2199023255551 milliseconds (ms) ~= 69年,调整起始时间点,将时间设置得更靠近当前时间可延时算法溢出的时间点。另外,在拿到一个ID后,也很容易推算出这个ID的生成时间,只需要加上既定时间点1288834974657,再转化成UTC秒数即可。
雪花算法的另一个问题是时间回拔问题,当服务器时间发生回拔时,会导致ID冲突,这在网上有很多介绍,以下是一些解决方案的描述:
使用雪花算法为分布式下全局ID、订单号等简单解决方案考虑到时钟回拨 - 星朝 - 博客园
时钟回拨问题咋解决?百度开源的唯一ID生成器UidGenerator - 知乎
| 目录 |
|---|