...
以下面的分布式系统为例,这里有n1~n3三个结点,数据需要同时在n1~n3上复制存储:

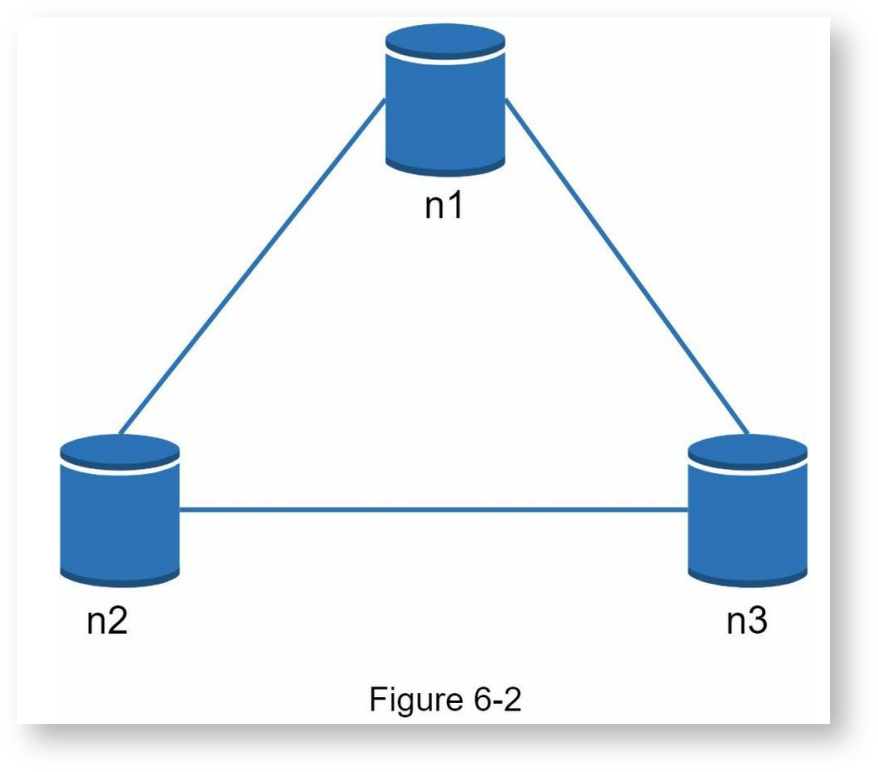
理想情况下,网络分区(network partiton)不会发生。写向n1的数据可以自动复制到n2和n3,一致性和可用性都能满足。
现实场景中,网络分区无法避免,当某个结点发生故障时(并不一定是宕机,也可能只是单纯因为网络问题导致与其他结点无法通信),系统必须在高可用性和高一致性之间作出选择,这里以n3出现故障为例进行说明:

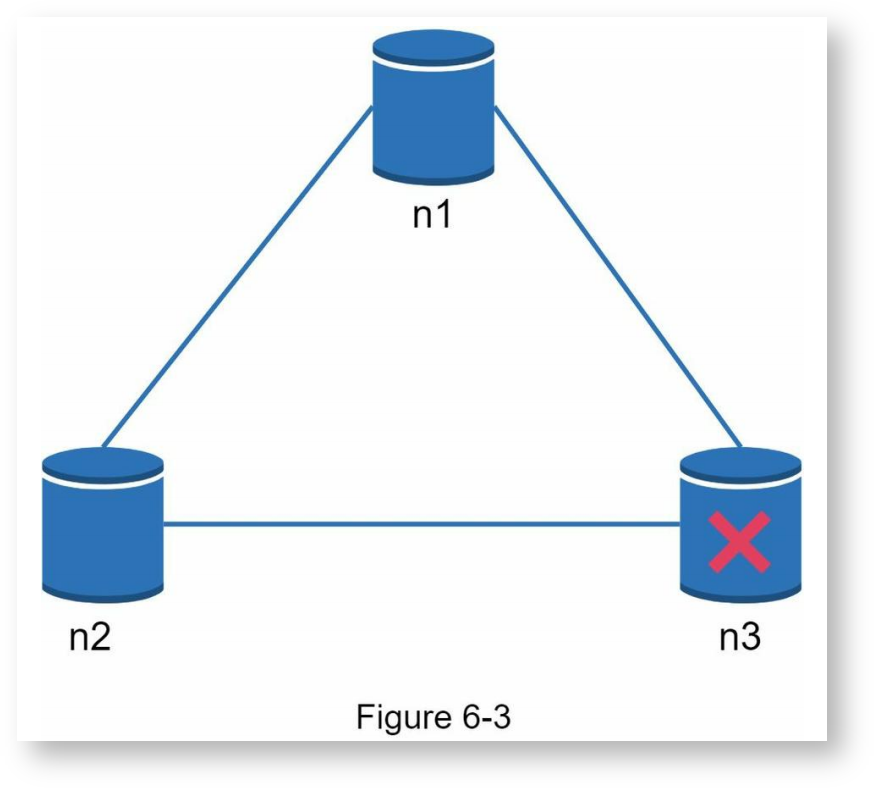
当n3出现故障时,如果客户端写n1和n2,那么数据不能被同步到n3,如果客户端写n3,那n1和n2无法从n3同步数据,即n1和n2的数据有可能过时。
如果系统优先考虑一致性,那当n3出现故障后,系统应该立即停止任何对n1和n2的写操作,以避免数据不一致,这就导致可用性无法满足。
如果系统优先考虑可用性,则n3出现故障后,n1和n2仍旧可供读写,但数据有可能是过时的,这就导致一致性无法满足。
应该根据实际应用场景来选择合适的CAP策略。
系统组件
讨论分布式键值数据库的核心组件:
- 数据分区
- 数据复制
- 一致性
- 非一致性问题处理
- 容错处理
- 系统架构图
- 写过程
- 读过程
数据分区
指的是将数据拆分成几部分存储在不同的服务器上,因为单个的服务器无法满足存储海量数据的需求。数据拆分有以下几项挑战:
- 将数据平均分布到各个服务器
- 在增加或删除服务器时,尽量减少数据的移动
前一章节讨论的一致性哈希可用于解决上述问题,这里简要描述一下过程:
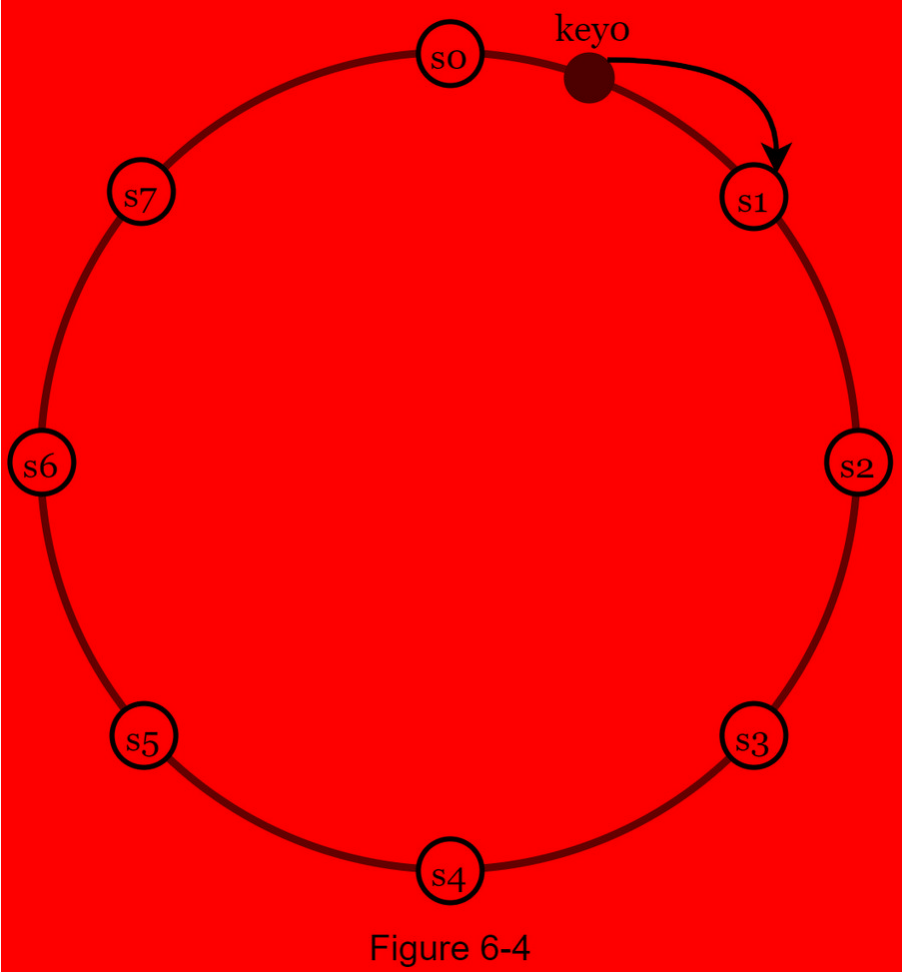
- 服务器按哈希值映射到哈希环上,下面的例子包含s0~s7共8个服务器
- 将key也按相同的哈希算法映射到哈希环上,并将数据存储在顺时钟方向上第一个相邻的服务器,这里存储在s1中。
根据负载情况,服务器可自动增加或删除。可按服务器的存储能力比例分配虚拟结点的数量,比如大容量的服务器可分配较多的虚拟结点。
数据复制
为提高可用性和可靠性,数据一般会通过异步复制技术存储在N台服务器上,N是一个可配置的参数。这里的N台服务器可以用下面的方式来选择:
- 当把key映射到哈希环上后,按顺时针方向选择前N个服务器进行存储,比如在下面的示例中,N=3,key0被存储在s1,s2,s3中
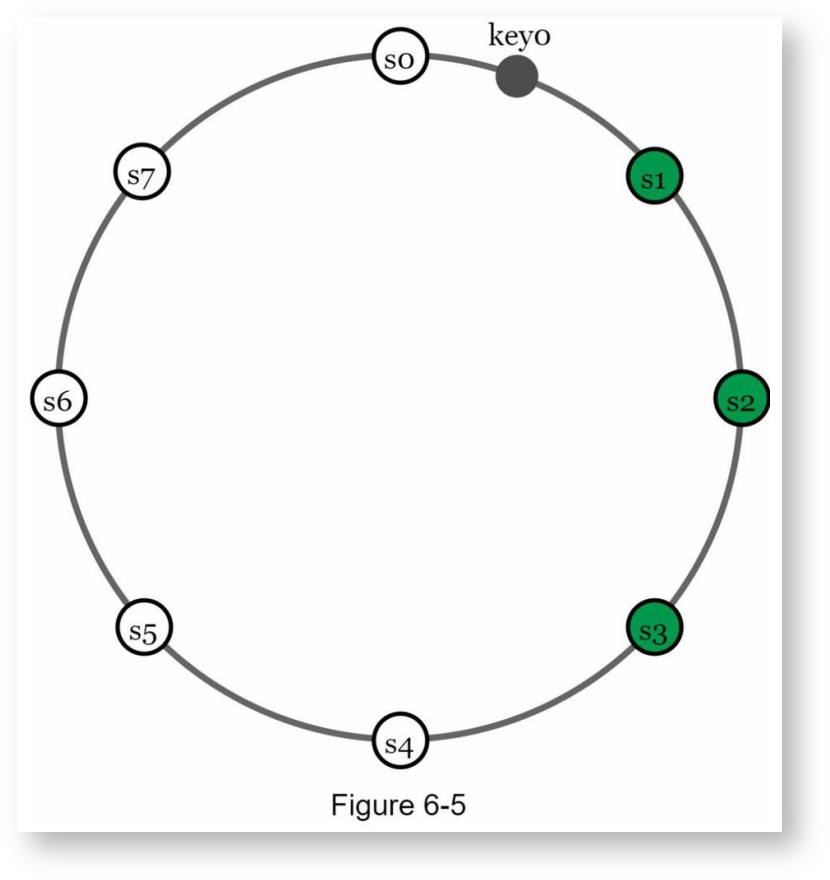
如果使用了虚拟结点,则在选择前N个服务器时应跳过属于同一个服务器的虚拟结点。
一致性
数据在多个结点之间复制时必须保证同步。Quorum机制(参考Quorum (分布式系统) - 维基百科,自由的百科全书)可用于保证在读写时的一致性。以下是一些相关的定义:
N = 复制数
W = 写票数,写操作需要至少收到W份写成功的响应才算写成功
R = 读票数,读操作需要至少收到R份读成功的响应才算写成功
以下面的示例来说明Quorum机制,这里N = 3。
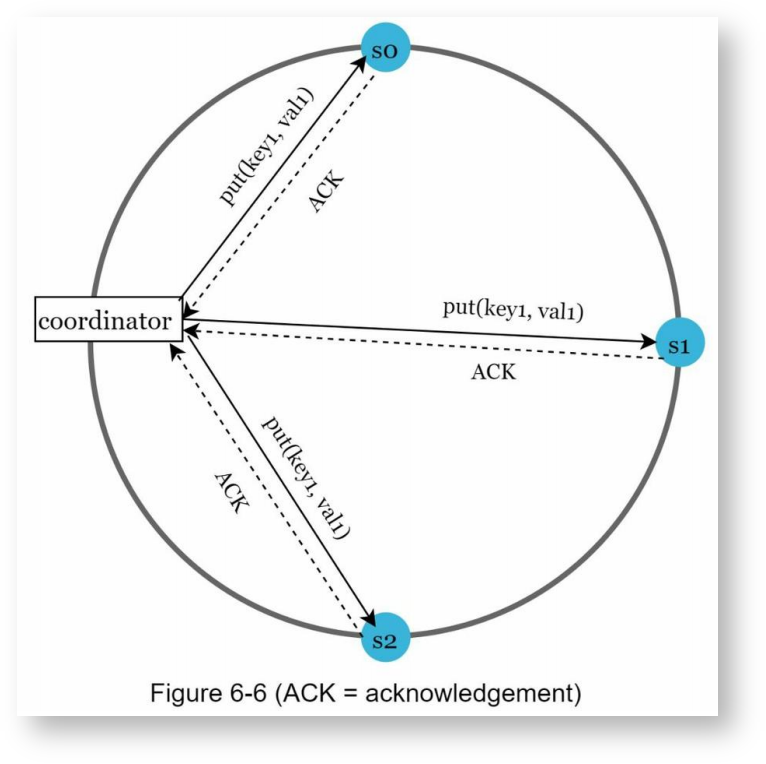
W = 1并不是表示数据只会存储在一个服务器上,而是指在写s0~s3时,必须收到至少一个写成功的响应,才会认为写成功,也就是说,数据有可能在s0~s3上都写成功了,但只要收到了其中一个的响应,写操作就会成功返回,而不再等待另外两个结点的响应。
对W, R, N的配置决定了系统的延时性和一致性。如果W=1或N=1,则任何读写操作都会快速返回,因为只要收到1个成功响应就认为操作成功。如果W或R大于1,则响应会慢一些,因为要等多个结点响应操作成功,但一致性会更好。
如果W + R > N, 则系统有较强的一致性,因为可以保证系统至少有一个重叠的结点存储的数据是最新的。以下是一些可能的W,N, R配置及其效果:
- 如果R = 1并且W = N,则系统优化为支持快速读取。
- 如果W = 1并且 R = N,则系统优化为支持快速写入。
- 如果W + R > N,则系统保证了较强的一致性(通常是N=3, W = R = 2)。
- 如果 W + R < N,则系统并不保证强一致性。
根据实际场景,可灵活配置W,R,N以适应需求。当n3出现故障时,如果客户端写n1和n2,那么数据不能被同步到n3,如果客户端写n3,那n1和n2无法从n3同步数据,即n1和n2的数据有可能过时。