基于epoll超时实现定时器功能,精度毫秒级,支持在指定超时时间结束之后执行回调函数。本章对应源码:https://github.com/zhongluqiang/sylar-from-scratch/releases/tag/v1.7.0。
《Linux高性能服务器编程.pdf》第11章对定时器有完整而详细地介绍,包括原理与代码实现,本文关于定时器的介绍与实现都是从这章摘抄的,目的只为了加深本人对定时器的理解。建议读者先阅读这章的内容,然后直接看sylar定时器的设计与实现,下面的定时器概述和几种定时器实现随便看看就好了。
定时器概述
通过定时器可以实现给服务器注册定时事件,这是服务器上经常要处理的一类事件,比如3秒后关闭一个连接,或是定期检测一个客户端的连接状态。
定时事件依赖于Linux提供的定时机制,它是驱动定时事件的原动力,目前Linux提供了以下几种可供程序利用的定时机制:
1. alarm()或setitimer(),这俩的本质都是先设置一个超时时间,然后等SIGALARM信号触发,通过捕获信号来判断超时
2. 套接字超时选项,对应SO_RECVTIMEO和SO_SNDTIMEO,通过errno来判断超时
3. 多路复用超时参数,select/poll/epoll都支持设置超时参数,通过判断返回值为0来判断超时
4. timer_create系统接口,实质也是借助信号,参考man 2 timer_create
5. timerfd_create系列接口,通过判断文件描述符可读来判断超时,可配合IO多路复用,参考man 2 timerfd_create
服务器程序通常需要处理众多定时事件,如何有效地组织与管理这些定时事件对服务器的性能至关重要。为此,我们要将每个定时事件分别封装成定时器,并使用某种容器类数据结构,比如链表、排序链表和时间轮,将所有定时器串联起来,以实现对定时事件的统一管理。
每个定时器通常至少包含两个成员:一个超时时间(相对时间或绝对时间)和一个任务回调函数。除此外,定时器还可以包括回调函数参数及是否自动重启等信息。
有两种高效管理定时器的容器:时间轮和时间堆,sylar使用时间堆的方式管理定时器。
几种定时器实现
基于升序链表的定时器
1. 所有定时器组织成链表结构,链表成员包含超时时间,回调函数,回调函数参数,以及链表指针域。
2. 定时器在链表中按超时时间进行升序排列,超时时间短的在前,长的在后。每次添加定时器时,都要按超时时间将定时器插入到链表的指定位置。
3. 程序运行后维护一个周期性触发的tick信号,比如利用alarm函数周期性触发ALARM信号,在信号处理函数中从头遍历定时器链表,判断定时器是否超时。如果定时器超时,则记录下该定时器,然后将其从链表中删除。
4. 执行所有超时的定时器的回调函数。
以上就是一个基于升序链表的定时器实现,这种方式添加定时器的时间复杂度是O(n),删除定时器的时间复杂度是O(1),执行定时任务的时间复杂度是O(1)。
tick信号的周期对定时器的性能有较大的影响,当tick信号周期较小时,定时器精度高,但CPU负担较高,因为要频繁执行信号处理函数;当tick信号周期较大时,CPU负担小,但定时精度差。
当定时器数量较多时,链表插入操作开销比较大。
时间轮
与上面的升序链表实现方式类似,也需要维护一个周期性触发的tick信号,但不同的是,定时器不再组织成单链表结构,而是按照超时时间,通过散列分布到不同的时间轮上,像下面这样:
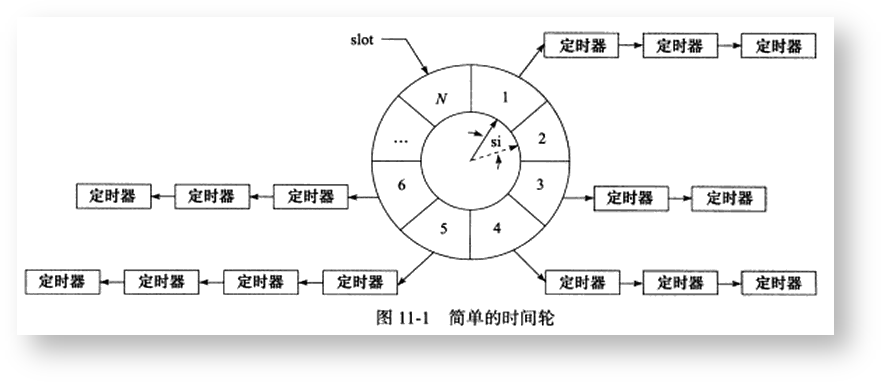
上面的时间轮包含N个槽位,每个槽位上都有一个定时器链表。时间轮以恒定的速度顺时针转动,每转一步,表盘上的指针就指向下一个槽位。每次转动对应一个tick,它的周期为si,一个共有N个槽,所以它运转一周的时间是N*si。
每个槽位都有一条定时器链表,同一条链表上的每个定时器都具有相同的特征:前后节点的定时时间相差N*si的整数倍。时间轮正是利用这个关系将定时器散列到不同的链表上。假如现在指针指向槽cs,我们要添加一个定时时间为ti的定时器,则该定时器将被插入槽ts(time slot)对应的链表中:
ts = (cs + (ti / si)) % N
时间轮通过哈希表的思想,将定时器散列到不同的链表上,每个链表的定时器数目都明显少于原来的排序链表,插入效率基本不受定时器数目的影响。
和升序链表一样,tick的周期将影响定时器精度和CPU负载,除此外,时间轮上的槽数量N还对定时器的效率有影响,N越大,则散列越均匀,插入效率越高,N越小,则散列越容易冲突,至N等于1时,时间轮将完全退化成升序链表。
上面的时间轮只有一个轮子,而复杂的时间轮可能有多个轮子,不同的轮子拥有不同的粒度。相邻的两个轮子,精度高的转一圈,精度低的仅往前移动一槽,就像水表一样。
注意点:
单个槽上的定时器链表仍然是按升序链表来组织的,只不过前后两个节点的时间差一定是N*si的整数倍。注意这里前后节点的时间差不一定是1个N*si,也有可能是好几个N*si,所以不能通过定时器所在的槽位和链表位置直接推算出定时器的超时时间。或者换个说法,表盘指针转到某个槽时,仍需要按升序链表的方式遍历这个链表的节点,并判断是否超时。
时间堆
上面的两种定时器设计都依赖一个固定周期触发的tick信号。设计定时器的另一种实现思路是直接将超时时间当作tick周期,具体操作是每次都取出所有定时器中超时时间最小的超时值作为一个tick,这样,一旦tick触发,超时时间最小的定时器必然到期。处理完已超时的定时器后,再从剩余的定时器中找出超时时间最小的一个,并将这个最小时间作为下一个tick,如此反复,就可以实现较为精确的定时。
最小堆很适合处理这种定时方案,将所有定时器按最小堆来组织,可以很方便地获取到当前的最小超时时间,sylar采取的即是这种方案。
sylar定时器设计
sylar的定时器采用最小堆设计,所有定时器根据绝对的超时时间点进行排序,每次取出离当前时间最近的一个超时时间点,计算出超时需要等待的时间,然后等待超时。超时时间到后,获取当前的绝对时间点,然后把最小堆里超时时间点小于这个时间点的定时器都收集起来,执行它们的回调函数。
注意,在注册定时事件时,一般提供的是相对时间,比如相对当前时间3秒后执行。sylar会根据传入的相对时间和当前的绝对时间计算出定时器超时时的绝对时间点,然后根据这个绝对时间点对定时器进行最小堆排序。因为依赖的是系统绝对时间,所以需要考虑校时因素,这点会在后面讨论。
sylar定时器的超时等待基于epoll_wait,精度只支持毫秒级,因为epoll_wait的超时精度也只有毫秒级。
关于定时器和IO协程调度器的整合。IO协程调度器的idle协程会在调度器空闲时阻塞在epoll_wait上,等待IO事件发生。在之前的代码里,epoll_wait具有固定的超时时间,这个值是5秒钟。加入定时器功能后,epoll_wait的超时时间改用当前定时器的最小超时时间来代替。epoll_wait返回后,根据当前的绝对时间把已超时的所有定时器收集起来,执行它们的回调函数。
由于epoll_wait的返回并不一定是超时引起的,也有可能是IO事件或是新调度任务的tickle唤醒的,所以在epoll_wait返回后还要再判断一轮定时器有没有超时,这就为什么要使用绝对时间的原因,通过比较当前的绝对时间和定时器的绝对超时时间,就可以知道一个定时器到底有没有超时。
sylar定时器实现
sylar的定时器对应Timer类,所有的Timer类都由TimerManager类管理,sylarIO协程调度模块通过继承的方式获得TimerManager类的所有方法,相当于给IOManager外挂了一个定时器管理模块。
sylar的定时器模块整体比较简单,只需要维护好所有的定时。
一点讨论
sylar的定时器以gettimeofday()来获取绝对时间点并判断超时,所以依赖系统时间,如果系统进行了校时,比如NTP时间同步,那这套定时机制就失效了。sylar的解决办法是设置一个较小的超时步长,比如3秒钟,也就是epoll_wait最多3秒超时,如果最近一个定时器的超时时间是10秒以后,那epoll_wait需要超时3次才会触发。每次超时之后除了要检查有没有要触发的定时器,还顺便检查一下系统时间有没有被往回调。如果系统时间往回调了1个小时以上,那就触发全部定时器。个人感觉这个办法有些粗糙,其实只需要换个时间源就可以解决校时问题,换成clock_gettime(CLOCK_MONOTONIC_RAW)的方式获取系统的单调时间,就可以解决这个问题了。
| 目录 |
|---|